Modelo dinámico de predicción del feminicidio con variables de denuncia en Perú
Dynamic femicide prediction model based on reported variables in Peru
Autores
Ruiz, Rubén Ángel
https://orcid.org/0000-0002-5159-3307
Universidad Continental, Perú
Venegas, Pedro B.
https://orcid.org/0000-0001-9806-6419
Universidad Continental, Perú
Calle, Margarita E.
https://orcid.org/0000-0001-5564-5488
Universidad Continental, Perú
Datos del artículo
Año | Year: 2026
Volumen | Volume: 14
Número | Issue: 1
DOI: https://doi.org/10.17502/mrcs.v14i1.920
Recibido | Received: 28-12-2025
Aceptado | Accepted: 8-5-2026
Primera página | First page: 1
Última página | Last page: 16
Resumen
El presente estudio analiza la dinámica predictiva del feminicidio en el Perú utilizando un panel de datos departamentales (2015-2023) con el objetivo de fortalecer los sistemas de alerta temprana y optimizar la respuesta estatal. Metodológicamente, se contrastó el desempeño de un modelo avanzado de aprendizaje automático, Gradient Boosting Regressor (GBR), frente al enfoque tradicional econométrico ARIMAX(1,0,0). Se implementó una rigurosa validación de ventana expandida (expanding window) y el test de Diebold-Mariano para evaluar la robustez y significancia de los pronósticos. Los resultados validaron la superioridad del GBR con un MAE de 0.313, logrando una reducción del error del 45% respecto a los métodos clásicos. El análisis de interpretabilidad mediante valores SHAP identificó que la inercia histórica del fenómeno constituye el principal predictor (62%), no obstante, las denuncias previas por violencia sexual y psicológica emergen como señales de alerta temprana más críticas que la violencia física. Se concluye que el modelado no lineal detecta ventanas de oportunidad para la intervención preventiva que los modelos lineales ignoran. Estos hallazgos exigen reorientar las políticas públicas con el propósito de contener la violencia sexual como precursor letal, asignando recursos basasdos en evidencia algorítmica con el fin de interrumpir el ciclo antes del desenlace fatal.
Palabras clave: feminicidio, aprendizaje automático, violencia de género, sistemas de alerta temprana, Perú,
Abstract
This study analyzes the predictive dynamics of femicide in Peru using a departmental data panel (2015-2023) to strengthen early warning systems and optimize state response. Methodologically, the performance of an advanced machine learning model, Gradient Boosting Regressor (GBR), was contrasted against the traditional econometric ARIMAX(1,0,0) approach. A rigorous expanding window validation and the Diebold-Mariano test were implemented to evaluate the temporal robustness and statistical significance of the forecasts. Results validated the superiority of the GBR with a Mean Absolute Error (MAE) of 0.313, achieving a 45% reduction in predictive error compared to classical methods. Interpretability analysis using SHAP values identified that the historical inertia of the phenomenon constitutes the main predictor (62%); however, prior reports of sexual and psychological violence emerge as more critical early warning signals than physical violence. It is concluded that non-linear modeling detects specific windows of preventive opportunity that linear models ignore. These findings suggest an urgent reorientation of public policies toward the containment of sexual violence as a lethal precursor. By allowing for an evidence-based algorithmic resource allocation, these models can effectively interrupt the cycle of violence before a fatal outcome occurs, closing the gap between formal reports and effective victim protection.
Key words: femicide, machine learning, gender-based violence, early warning systems, Peru,
Cómo citar este artículo
Ruiz, R. A., Venegas, P. B., y Calle, M. E. (2026). Un modelo dinámico de predicción del feminicidio con variables de denuncia en Perú. methaodos.revista de ciencias sociales, 14(1), m261401n01. https://doi.org/10.17502/mrcs.v14i1.920
Contenido del artículo
1. Introducción
La violencia contra la mujer (VCM) constituye una de las violaciones de derechos humanos más persistentes, sistemáticas y devastadoras a nivel global. Lejos de ser un conflicto privado, se configura como un problema estructural de salud pública. Se estima que aproximadamente 736 millones de mujeres en todo el mundo, es decir, casi una de cada tres han sido víctimas de violencia física o sexual por parte de su pareja íntima, violencia sexual por otros agresores, o ambas, al menos una vez en su vida (ONU Mujeres, 2023)Ref17. Este fenómeno se define estructuralmente como cualquier acto de agresión basado en la pertenencia al sexo femenino que tenga como resultado un daño o sufrimiento físico, sexual o psicológico para la mujer, así como las amenazas de tales actos, la coacción o la privación arbitraria de la libertad, tanto en la vida pública como en la privada (Naciones Unidas, 1993)Ref16.
En América Latina y el Caribe, la problemática adquiere matices críticos debido a factores culturales arraigados y desigualdades estructurales. Según datos comparativos de la Organización Panamericana de la Salud (OPS) y los Centros para el Control y la Prevención de Enfermedades (2014)Ref18, en los 12 países de la región estudiados, entre el 17% y el 53% de las mujeres reportaron haber sufrido violencia física o sexual por parte de su pareja en algún momento de su vida. Además, entre un 10% y un 27% han sido víctimas de violencia sexual por otros agresores, mayoritariamente conocidos. Más alarmante aún es el desenlace fatal de esta violencia: en 2023, la Comisión Económica para América Latina y el Caribe (CEPAL, 2024)Ref2 reportó tres 897 mujeres asesinadas por razones de género en 27 países, lo que equivale a un promedio de 11 feminicidios diarios. De esos casos, la inmensa mayoría (3 877) ocurrieron en América Latina, confirmando a la región como una de las zonas más peligrosas del mundo para las mujeres fuera de contextos de guerra.
La tendencia temporal es igualmente preocupante. Entre 2015 y 2023, países como Paraguay, Puerto Rico, México, Ecuador, Honduras y Perú mostraron incrementos sostenidos en sus tasas de feminicidio. En el caso específico de Paraguay, se observó el mayor crecimiento con un aumento de 0,7 puntos porcentuales. Un patrón constante en estos crímenes es la relación víctima-victimario: en más del 60% de los casos registrados por la CEPAL, el agresor fue la pareja o expareja de la víctima. Asimismo, aunque la violencia afecta desproporcionadamente a mujeres de entre 30 y 59 años (56,4%), no discrimina etapas vitales, impactando severamente a jóvenes de 15 a 29 años (20,3%), niñas menores de 14 años (3,4%) y adultas mayores, lo que evidencia la transversalidad del riesgo a lo largo del ciclo de vida.
En el contexto específico del Perú, las cifras sobre la violencia contra las mujeres se mantienen en niveles alarmantes, revelando una brecha significativa entre la protección formal de la ley y la realidad vivida en los territorios. Durante el año 2023, el 53,8% de las mujeres entre 15 y 49 años reportaron haber sido víctimas de violencia conyugal alguna vez en su vida (INEI, 2024b)[ref11]. El análisis territorial de esta violencia revela una heterogeneidad significativa que responde a dinámicas socioculturales y económicas diversas. A nivel departamental, los porcentajes más elevados de mujeres en edad fértil que sufrieron algún tipo de violencia por parte de su esposo o compañero se registraron en Apurímac (67,4%), Tumbes (60,4%), Madre de Dios (59,5%) y Junín (57,4%). Estas cifras sugieren que factores como la ruralidad, la presencia de economías ilegales (como la minería en Madre de Dios) y patrones culturales andinos o costeros interactúan de formas complejas para exacerbar la vulnerabilidad de las mujeres.
En cuanto al feminicidio, el Perú registró 146 casos validados a nivel nacional en 2023, lo que representa una tasa de 0,9 por cada 100 000 mujeres, manteniéndose en el mismo nivel crítico que en los años 2022 y 2019. Paradójicamente, Perú cuenta con un marco normativo robusto. La Ley N.° 30364 (Congreso de la República del Perú, 2015)Ref3 y la creación del Sistema Nacional Especializado de Justicia (SNEJ) mediante el Decreto Legislativo N.º 1368 (Presidencia de la República del Perú, 2018)Ref19 prometieron una atención integral y oportuna. Sin embargo, reportes de la Defensoría del Pueblo (2023)Ref5 y del MIMP (2025)Ref15 alertan sobre una desconexión crítica: casi una cuarta parte (24,2%) de las víctimas de feminicidio entre 2018 y 2023 ya había interpuesto denuncias previas contra su agresor. Este dato implica que el sistema estatal tuvo conocimiento del riesgo y falló en proteger la vida de la víctima.
Históricamente, la predicción del riesgo letal ha dependido de herramientas actuariales (como el EPV-R) o de juicio profesional estructurado (como el sistema VioGén en España o el Danger Assessment). Si bien útiles, diversos estudios (Loinaz, 2025Ref13; Viñas-Racionero et al., 2025Ref24) señalan que estas herramientas presentan limitaciones intrínsecas: tienden a ser estáticas, dependen de la subjetividad del evaluador y tienen dificultades para procesar grandes volúmenes de datos en tiempo real o para incorporar interacciones no lineales complejas entre factores de riesgo.
Frente a estas limitaciones, la selección del algoritmo adecuado es crítica. Si bien la Regresión Logística es valorada por su sencillez, resulta insuficiente ante la complejidad del feminicidio. Los Árboles de Decisión son interpretables pero inestables. Las Redes Neuronales son potentes pero actúan como "cajas negras". En contraste, este estudio selecciona el Gradient Boosting Regressor (GBR) debido a su equilibrio óptimo: ofrece una altísima precisión al corregir secuencialmente errores, captura no linealidades mejor que los modelos estadísticos, y es compatible con técnicas de interpretabilidad avanzadas como SHAP. Este enfoque se contrastará con un modelo ARIMAX, el estándar tradicional en series temporales, para probar empíricamente si la complejidad algorítmica aporta valor real sobre los métodos clásicos.
Bajo este marco, el objetivo general de la investigación es desarrollar y validar un modelo predictivo basado en Gradient Boosting Regressor para anticipar casos críticos de feminicidio en el Perú (2015-2023), utilizando variables históricas de denuncias y factores contextuales. Se plantean las siguientes hipótesis de investigación:
H1: El uso de algoritmos avanzados de Machine Learning, específicamente Gradient Boosting Regressor, mejora significativamente la precisión predictiva del riesgo de feminicidio comparado con métodos tradicionales estadísticos como el ARIMAX, al capturar mejor la complejidad no lineal del fenómeno.
H2: Las denuncias previas por los distintos tipos de violencia contra la mujer constituyen predictores críticos con alta relevancia estadística para anticipar feminicidios en los modelos de aprendizaje automático.
H3: El empleo de técnicas interpretativas como SHAP permitirá identificar variables clave y "ventanas de oportunidad" que informen de manera efectiva a las instituciones públicas, facilitando intervenciones oportunas y focalizadas antes del desenlace fatal.
2. Marco Teórico
El feminicidio no es un evento estocástico ni aislado; es el corolario de procesos estructurales y relacionales que han sido ampliamente teorizados. Para la construcción del modelo predictivo de este estudio, se han operacionalizado tres enfoques teóricos fundamentales que justifican la selección de las variables predictoras.
Propuesto originalmente por Lori Heise (1998)Ref8, este modelo supera las explicaciones monocausales (que atribuyen la violencia solo a la patología del agresor) para situarla en la intersección de cuatro sistemas anidados.
En el microsistema (historia personal), factores como el haber sido testigo de violencia en la infancia aumentan la probabilidad de perpetración. En el mesosistema (relaciones cercanas), el conflicto marital severo y el control de la riqueza por parte del varón son predictores clave. En el exosistema (comunidad), el aislamiento social de la mujer y las redes de pares masculinos que condonan la violencia actúan como facilitadores. Finalmente, en el macrosistema, las normas culturales que otorgan al hombre "derecho de propiedad" sobre la mujer legitiman el uso de la fuerza.
La relevancia de este modelo para nuestra investigación radica en su validación de los factores contextuales: el riesgo de feminicidio no es igual en un entorno urbano con redes de apoyo que en un entorno rural aislado (como se modela con la variable de densidad poblacional).
Evan Stark (2007)Ref22 revolucionó la criminología al definir la violencia doméstica no como una serie de agresiones ("peleas"), sino como un "crimen contra la libertad". El control coercitivo es un patrón estratégico de comportamiento que busca anular la autonomía de la víctima mediante tácticas de intimidación, degradación, aislamiento y control.
Bajo esta óptica, el feminicidio se produce a menudo cuando el agresor percibe que está perdiendo ese control (por ejemplo, cuando la mujer intenta separarse o denuncia). Esto otorga una importancia capital a las variables de violencia psicológica y económica, que nuestro modelo incorpora. A diferencia de la violencia física, que puede ser episódica, el control coercitivo es continuo ("estado de sitio"), lo que lo convierte en un predictor de letalidad más estable y peligroso, aunque frecuentemente subestimado por los sistemas judiciales tradicionales.
Leonore Walker (1979)Ref25 identificó la dinámica cíclica del abuso: (1) Fase de acumulación de tensión, caracterizada por agresiones verbales y psicológicas menores; (2) Fase de explosión aguda, donde ocurre la violencia física o sexual grave; y (3) Fase de luna de miel, donde el agresor muestra arrepentimiento y la víctima retira denuncias o perdona.
Para los sistemas de alerta temprana, el desafío reside en detectar el riesgo durante la fase 1. Nuestro modelo incorpora variables rezagadas (t - 1) precisamente para capturar esa "acumulación de tensión" previa. Si el sistema solo reacciona ante la "explosión" (fase 2), la intervención suele llegar demasiado tarde para prevenir el feminicidio.
La transición de modelos estadísticos tradicionales a técnicas de Machine Learning (ML) en la criminología ha generado un cuerpo de literatura reciente que evidencia tanto el potencial como los desafíos de estas herramientas.
En Europa, la investigación se ha centrado en la explotación de grandes bases de datos policiales. Rodríguez-Rodríguez et al. (2020)Ref20, en España, analizaron más de una década de denuncias del sistema VioGén. Su estudio demostró que los modelos de Random Forest superaban consistentemente a la regresión logística en la predicción de reincidencia. Sin embargo, una limitación crítica hallada fue la "ceguera al contexto": los modelos predecían bien basándose en antecedentes penales, pero fallaban al integrar factores sociales dinámicos (empleo, red de apoyo) que no constan en los atestados policiales. Por otro lado, González-Prieto et al. (2023)Ref7 abordaron el problema de los "falsos negativos" (casos clasificados como de bajo riesgo que terminan en feminicidio). Propusieron un enfoque híbrido que combina reglas de expertos con clasificación automática, concluyendo que la intuición policial es valiosa pero inconsistente, y que el algoritmo debe actuar como una "segunda opinión" objetiva para reducir la variabilidad humana.
En nuestra región, la aplicación de ML enfrenta el desafío adicional de la calidad de los datos. En Colombia, Bernal-Monroy et al. (2025)Ref1 desarrollaron un modelo integrado al sistema de vigilancia SIVIGILA. Su innovación principal fue incluir variables de salud mental (intentos de suicidio de la víctima) como precursores de feminicidio, logrando identificar perfiles de riesgo que los protocolos estándar ignoraban.
En México, Cruz-Mendoza et al. (2025)Ref4 realizaron un benchmark exhaustivo de algoritmos (Decision Trees, SVM, GBM) sobre datos de la Encuesta Nacional sobre la Dinámica de las Relaciones en los Hogares. Su hallazgo más relevante para nuestro estudio fue la superioridad del Gradient Boosting (AUC > 0.98) para manejar datos desbalanceados (donde hay muchos casos de violencia pero pocos feminicidios), validando nuestra elección metodológica.
Finalmente, en Brasil, Lima y Almeida de Oliveira (2024)Ref12 exploraron el uso de Deep Learning (redes LSTM) para analizar el texto libre de los reportes policiales. Aunque prometedor, encontraron que la jerga policial y los errores de escritura limitaban la capacidad del modelo, sugiriendo que, por el momento, los datos estructurados (conteos, tipos de violencia) siguen siendo más fiables para la implementación a gran escala.
En el Perú, el estudio pionero de Saboya, Sullón y Loaiza (2019)Ref21 marcó un hito al aplicar minería de datos a la encuesta ENDES, perfilando víctimas con Random Forest. No obstante, su diseño transversal presentó una limitación fundamental: al usar una encuesta, no podían rastrear la evolución temporal ni conectarla con las denuncias. El presente estudio busca llenar ese vacío utilizando un diseño longitudinal de datos de panel, aportando la dimensión temporal que faltaba en la literatura nacional.
La viabilidad de implementar modelos predictivos en el Perú debe analizarse a la luz de su marco legal y operativo. Si bien la Ley N.º 30364 (Congreso de la República del Perú, 2015)Ref3 establece un enfoque garantista y obliga a la evaluación de riesgo en todas las denuncias, la realidad operativa dista del mandato legal. Informes de la Defensoría del Pueblo (2023)Ref5 revelan cuellos de botella críticos, como la falta de interoperabilidad entre la Policía Nacional y el Ministerio Público, y la saturación de los Centros de Emergencia Mujer (CEM).
Actualmente, la valoración de riesgo se realiza mediante una ficha manual ("Ficha de Valoración de Riesgo") aplicada por operadores que a menudo carecen de herramientas tecnológicas, resultando en una subestimación del peligro, especialmente cuando no hay lesiones físicas visibles. La propuesta de este artículo, de automatizar la detección de patrones de riesgo mediante IA, busca modernizar este proceso para reducir la discrecionalidad y el error humano, cerrando la brecha entre la denuncia formal y la protección efectiva.
3. Metodología
Se desarrolló un estudio longitudinal retrospectivo con un enfoque analítico-predictivo, diseñado para modelar y anticipar el comportamiento de las tasas departamentales de feminicidio en el Perú durante el período 2015-2023. Desde una perspectiva epistemológica, el diseño adopta una postura integradora que combina la robustez inferencial de la econometría clásica con la capacidad predictiva de la ciencia de datos moderna.
El diseño metodológico se estructura como un análisis de datos de panel (panel data), donde la unidad de análisis corresponde a los 25 departamentos del territorio peruano observados a lo largo de 9 años. Esta estructura generó un panel balanceado con 225 observaciones totales (N=25×9), lo que permite capturar simultáneamente la heterogeneidad transversal (diferencias entre regiones como Lima y Madre de Dios) y la dinámica longitudinal (evolución temporal de la violencia en una misma región). La elección de este diseño responde a la naturaleza dual del feminicidio: es un fenómeno con fuerte inercia histórica (dependencia temporal) y, a la vez, está condicionado por factores estructurales propios de cada territorio.
La construcción del dataset se fundamentó en la integración y curación de registros administrativos oficiales, priorizando fuentes gubernamentales para garantizar la fiabilidad y reproducibilidad del estudio.
-Variables de violencia y respuesta institucional: se obtuvieron de los registros del Ministerio de la Mujer y Poblaciones Vulnerables (MIMP)Ref15, específicamente de los Centros de Emergencia Mujer (CEM). Estos datos documentan las atenciones por violencia y las denuncias interpuestas, sirviendo como proxies de la prevalencia de violencia de género.
-Indicadores demográficos y de control: proceden de las bases de datos del Instituto Nacional de Estadística e Informática (INEI, 2024a)Ref10, permitiendo normalizar las tasas por población y controlar por densidad demográfica.
La variable dependiente se operacionalizó como la tasa de feminicidios por cada 100 000 mujeres. Se optó por la tasa estandarizada en lugar del conteo absoluto para neutralizar el sesgo poblacional, permitiendo comparaciones válidas entre departamentos demográficamente dispares (ej., Lima Metropolitana vs. Moquegua).
3.1. Operacionalización de variables y justificación teórica
Las variables predictoras se seleccionaron bajo un criterio teórico basado en la escalada de la violencia y se estructuraron en cuatro dimensiones:
-Indicadores de violencia previa (Precursores): se incluyeron los conteos anuales de casos atendidos por violencia psicológica, física, sexual y económica. Para capturar la causalidad temporal y evitar la endogeneidad simultánea, se incorporaron tres versiones de cada variable:
Valor contemporáneo (t): Refleja la correlación inmediata.
Valor rezagado (t-1): Fundamental para probar la hipótesis de la "ventana de oportunidad", asumiendo que la violencia ocurrida en el año anterior es un predictor del feminicidio actual.
Transformaciones logarítmicas: Para manejar la no linealidad en la escala de los datos.
-Respuesta institucional: operacionalizada mediante el número de denuncias policiales y en CEM. La inclusión de esta variable busca testear la hipótesis de la "paradoja de la denuncia": determinar si un mayor número de denuncias actúa como factor de protección (reducción de feminicidios) o si, por ineficacia estatal, simplemente correlaciona con mayor violencia.
-Factores contextuales Se incluyó el logaritmo de la densidad poblacional como proxy de urbanidad/ruralidad. Además, se generó una variable dummy estructural para el período COVID-19 (valor 1 para los años 2020 y 2021; 0 para el resto), con el fin de aislar el efecto del confinamiento obligatorio sobre las dinámicas de violencia intrafamiliar.
-Control de heterogeneidad: Se implementaron efectos fijos departamentales mediante 24 variables dummy. Esta técnica econométrica permite controlar por todas aquellas características culturales, geográficas o institucionales propias de cada departamento que son invariantes en el tiempo (como la cultura local o la geografía difícil), evitando que estos factores no observados sesguen las estimaciones.
3.2. Protocolo de preprocesamiento y depuración de datos
El aseguramiento de la calidad de los datos incluyó etapas críticas de transformación matemática para adecuar la información a los requerimientos de los algoritmos. Dado que los datos criminales suelen presentar distribuciones de "cola pesada" (heavy-tailed) y sobredispersión (la varianza es mayor que la media), se aplicó una transformación logarítmica suavizada para estabilizar la varianza y aproximar las distribuciones a la normalidad. Esta transformación se define formalmente como:
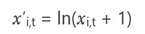
Donde xi,t representa el conteo de denuncias o víctimas en el departamento i en el año t, y la constante 1 se añade para evitar indefiniciones matemáticas (ln (0)) en departamentos con cero casos registrados en un año específico.
Complementariamente, la creación de variables rezagadas (t-1) generó valores perdidos (missing values) en el primer año de la serie. Para su manejo, se implementó una estrategia de imputación robusta por mediana, ejecutada mediante el estimador SimpleImputer de la librería Scikit-learn. A diferencia de la imputación por media aritmética, la mediana es resistente a los valores atípicos (outliers), preservando mejor la tendencia central en datos asimétricos.
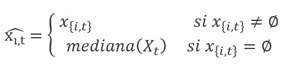
Finalmente, se verificó la estacionariedad de las series temporales resultantes mediante la prueba de Dickey-Fuller Aumentada (ADF), paso indispensable para asegurar que las propiedades estadísticas del modelo (media y varianza) sean constantes en el tiempo y evitar regresiones espurias.
3.3. Estrategia de modelado predictivo
El núcleo analítico del estudio contrastó dos paradigmas de modelado para evaluar cuál captura mejor la complejidad del feminicidio.
-Enfoque econométrico tradicional: se implementó un modelo ARIMAX (AutoRegressive Integrated Moving Average with eXogenous variables), especificado como ARIMAX(1,0,0). Este modelo representa el enfoque clásico de series de tiempo. Matemáticamente, asume que la tasa de feminicidio actual (Yt) es una función lineal de su propio pasado (Yt-1) y de variables externas (Xt):
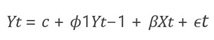
Donde ϕ1 es el coeficiente autorregresivo y β representa el vector de coeficientes para las variables exógenas (denuncias, violencia previa, etc.). La selección del orden (1,0,0) se basó en la minimización de los Criterios de Información de Akaike (AIC) y Bayesiano (BIC), priorizando la parsimonia. Este modelo sirvió como línea base (baseline), bajo el supuesto de linealidad y aditividad de los efectos.
-Enfoque de aprendizaje automático: Gradient Boosting Regressor Como propuesta innovadora, se empleó el Gradient Boosting Regressor (GBR). A diferencia de los modelos lineales, el GBR es un método de ensamble que construye un modelo predictivo robusto mediante la combinación secuencial de modelos débiles (árboles de decisión). El algoritmo opera minimizando una función de pérdida (en este caso, el error cuadrático) mediante el descenso de gradiente. En cada iteración, se añade un nuevo árbol que intenta predecir los "residuos" o errores cometidos por la combinación de árboles anteriores. Esto permite que el modelo se "especialice" en los casos más difíciles de predecir, capturando interacciones no lineales complejas (por ejemplo, cómo el efecto de las denuncias varía según la densidad poblacional) que el modelo ARIMAX ignora. La optimización de hiperparámetros se realizó mediante Grid Search con validación cruzada temporal, resultando en la siguiente configuración óptima: 200 estimadores (número de árboles), una tasa de aprendizaje (learning rate) de 0.1 (para evitar el sobreajuste), una profundidad máxima de 4 (permitiendo interacciones de hasta cuarto orden) y un submuestreo de 1.0.
3.4. Esquema de validación y métricas de desempeño
Para garantizar la validez externa de los resultados y evitar la filtración de datos (data leakage), se diseñó un esquema de validación temporal estricto ("Walk-Forward Validation"). El conjunto de entrenamiento comprendió el período histórico 2015-2021, mientras que los años 2022 y 2023 se mantuvieron "ocultos" al modelo, reservándolos exclusivamente para la prueba final.
Adicionalmente, se aplicó la técnica de ventana expandida (expanding window cross-validation) para los años 2019, 2020 y 2021. Esta técnica simula un escenario realista de formulación de políticas públicas: en 2019, el modelo se entrena con datos hasta 2018 y predice 2019; luego, se incorporan los datos reales de 2019, se reentrena y se predice 2020, y así sucesivamente. Esto permite evaluar la estabilidad del modelo ante cambios estructurales.
La evaluación se basó en un conjunto multidimensional de métricas:
-RMSE (Error Cuadrático Medio Raíz) y MAE (Error Absoluto Medio): miden la magnitud del error en las mismas unidades que la variable objetivo. El RMSE penaliza más severamente los errores grandes, lo cual es crítico en contextos donde subestimar un pico de violencia puede costar vidas.
-MASE (Error Escalado Absoluto Medio): permite comparar el desempeño del modelo frente a un modelo "ingenuo" (naive) que simplemente pronostica el valor del año anterior. Un MASE < 1 indica que el modelo aporta valor predictivo real.
-Desviación de Poisson: métrica seleccionada específicamente por la naturaleza de los datos (conteos de eventos raros), evaluando qué tan bien se ajusta la distribución predicha a la distribución real de los feminicidios.
La significancia estadística de la superioridad de un modelo sobre otro se determinó formalmente mediante el test de Diebold-Mariano, evaluando si la diferencia en la precisión predictiva es sistemática o producto del azar.
3.5. Interpretabilidad del modelo mediante teoría de juegos (SHAP)
Dado que los modelos de Gradient Boosting son a menudo criticados por su opacidad ("caja negra"), se implementó el análisis de valores SHAP (Shapley Additive exPlanations). Esta técnica, fundamentada en la teoría de juegos cooperativos, resuelve el problema de la asignación de crédito entre variables (Lundberg y Lee, 2017)Ref14. Este enfoque asume que la predicción del modelo es un "pago" que debe repartirse de manera justa entre los "jugadores" (las variables predictoras). El valor SHAP de una variable representa cuánto cambia la predicción del modelo cuando esa variable es observada, promediando sobre todas las posibles combinaciones de las otras variables. Esto permitió descomponer el riesgo de feminicidio en sus componentes constituyentes, identificando no solo qué variables son importantes globalmente, sino cómo influyen en cada predicción individual.
El estudio se condujo bajo estrictos principios éticos para la investigación con datos sensibles. Se utilizaron exclusivamente datos agregados y anonimizados a nivel departamental, eliminando cualquier posibilidad de reidentificación de las víctimas. Se reconocen limitaciones inherentes a las fuentes secundarias, principalmente el subregistro ("cifra negra") en áreas rurales con baja presencia estatal, lo que podría introducir un sesgo de subestimación en las tasas oficiales. Asimismo, se advierte explícitamente que la identificación algorítmica de zonas de alto riesgo debe utilizarse como una herramienta de apoyo para la asignación eficiente de recursos preventivos y nunca para la estigmatización territorial o la vigilancia punitiva de poblaciones vulnerables.
4. Resultados
4.1. Desempeño predictivo comparativo
El análisis comparativo entre el modelo ARIMAX(1,0,0) tradicional y el Gradient Boosting Regressor (GBR) reveló diferencias sustanciales en la capacidad de predicción de tasas de feminicidio para el período 2022-2023. Como se observa en la Figura 1, el modelo GBR demostró superioridad consistente a través de todas las métricas evaluadas, con mejoras que oscilan entre 45% y 81% dependiendo de la medida específica de desempeño.
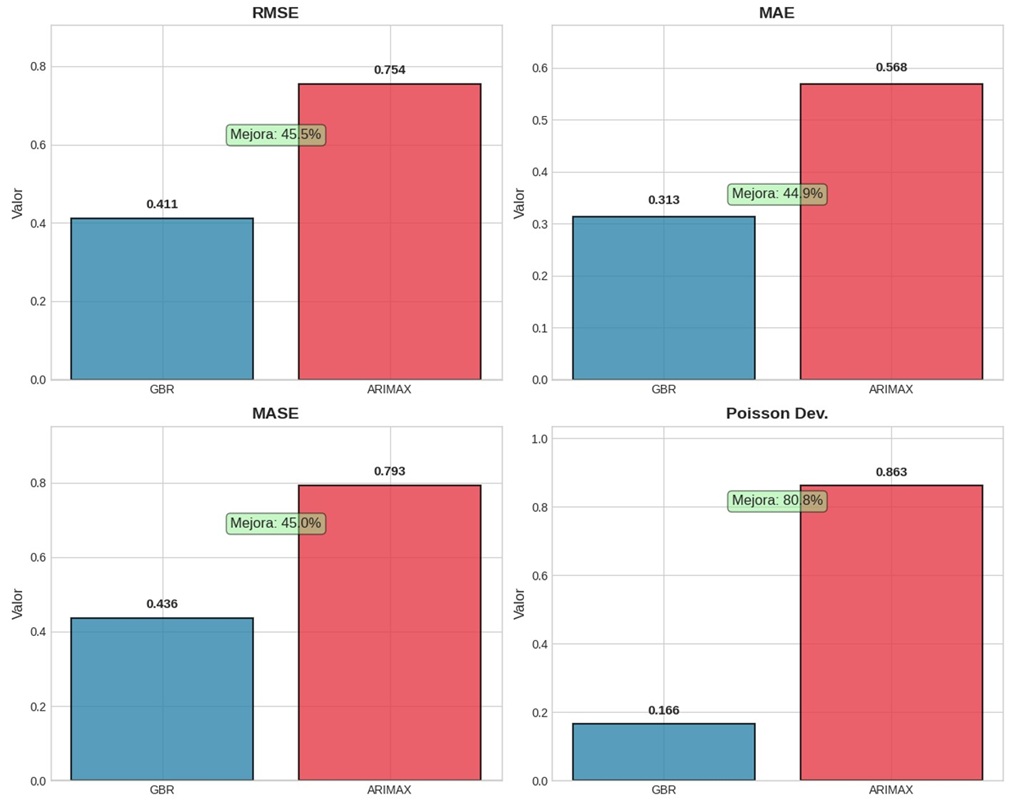
El Error Cuadrático Medio Raíz (RMSE) del GBR fue 0.411, comparado con 0.754 del modelo ARIMAX, representando una reducción del 45.5% en el error predictivo. Esta mejora sustancial indica que las predicciones del GBR se desvían en promedio menos de la mitad que las del modelo tradicional. De manera similar, el Error Absoluto Medio (MAE) mostró un patrón análogo, con valores de 0.313 para GBR versus 0.568 para ARIMAX. En términos prácticos, esto significa que el modelo de machine learning predice las tasas de feminicidio con un error promedio de solo 0.31 casos por cada 100,000 mujeres, mientras que el modelo tradicional duplica el nivel de error .
Un resultado revelador es el que se obtiene por Mean Absolute Scaled Error (MASE), donde el GBR obtuvo 0.436 comparado con 0.793 del ARIMAX. Un MASE inferior a 0.5 tiene la siguiente interpretación: el modelo GBR es más del doble de preciso que un modelo naive que simplemente utilizaría la tasa del año anterior como predicción. Este hallazgo valida la complejidad adicional del modelo de machine learning, demostrando que captura patrones significativos más allá de la simple persistencia temporal.
La métrica más resaltante fue la desviación de Poisson, donde el GBR alcanzó 0.166 versus 0.863 del ARIMAX, una reducción del 80.8%. Esta métrica es especialmente relevante dado que los feminicidios son eventos de conteo discreto. La mejora sustancial sugiere que el GBR captura de manera más apropiada la naturaleza estadística inherente de estos eventos raros pero trágicos, modelando mejor tanto la media como la varianza del proceso generador de datos.
4.2. Diagnóstico de residuales del modelo base
Antes de analizar la robustez temporal de los modelos, es importante verificar que el modelo ARIMAX cumple con sus supuestos fundamentales. La Figura 2 presenta el análisis exhaustivo de residuales del modelo ARIMAX para el período de prueba 2022-2023. La primera gráfica muestra la serie temporal de residuales, en ella se observa un comportamiento aparentemente aleatorio alrededor de cero, aunque con algunos valores extremos notables, particularmente un residual cercano a -1.8 que podría corresponder a una sección con características atípicas.
El segundo gráfico de la Figura 2 muestra la función de autocorrelación (ACF) de los residuales, donde todas las autocorrelaciones se encuentran dentro de las bandas de confianza al 95%. Este patrón visual es confirmado por el test de Ljung-Box, que con un estadístico de 5.031 y un p-valor de 0.889 no rechaza la hipótesis nula de independencia serial. La ausencia de autocorrelación significativa indica que el componente AR(1) del modelo captura adecuadamente la estructura de dependencia temporal en los datos.
La tercera gráfica presenta el histograma de residuales, mostrando una distribución aproximadamente simétrica centrada en cero. El test de Anderson-Darling arrojó un p-valor de 0.450, confirmando robustamente la hipótesis de normalidad (p > 0.05). Esto valida que el modelo ARIMAX cumple satisfactoriamente con los supuestos distribucionales necesarios para la inferencia estadística.
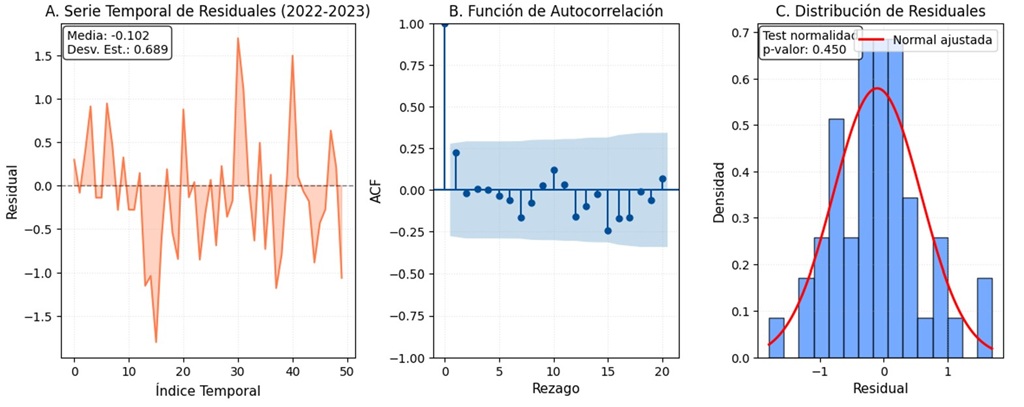
A pesar del cumplimiento general de los supuestos estadísticos, el desempeño predictivo inferior del ARIMAX comparado con el GBR sugiere que las relaciones lineales asumidas por el modelo tradicional no capturan adecuadamente la complejidad multidimensional del fenómeno feminicidio.
4.3. Estabilidad temporal y robustez
El Gráfico 1 ilustra de manera contundente la consistencia en el desempeño superior del GBR a través del tiempo mediante la validación con ventana temporal expandida. Este análisis es crucial para establecer que la superioridad del modelo de machine learning no es un artilugio del período específico elegido para la prueba, sino una característica robusta y generalizable.
Para el año 2019, entrenando únicamente con datos 2015-2018, el GBR logró un RMSE de 0.509 mientras que ARIMAX alcanzó 0.942. Esta diferencia inicial de 46% en favor del GBR establece un patrón que se mantendría consistente. El año 2020 presenta un caso particularmente interesante: coincidiendo con el inicio de la pandemia COVID-19 y las medidas de confinamiento, el GBR demostró su mejor desempeño absoluto con un RMSE de 0.439. Esto sugiere que el modelo capturó efectivamente los cambios en los patrones de violencia durante este período excepcional, posiblemente debido a su capacidad para modelar interacciones no lineales entre variables como el confinamiento (capturado por la variable dummy COVID) y los diferentes tipos de violencia.
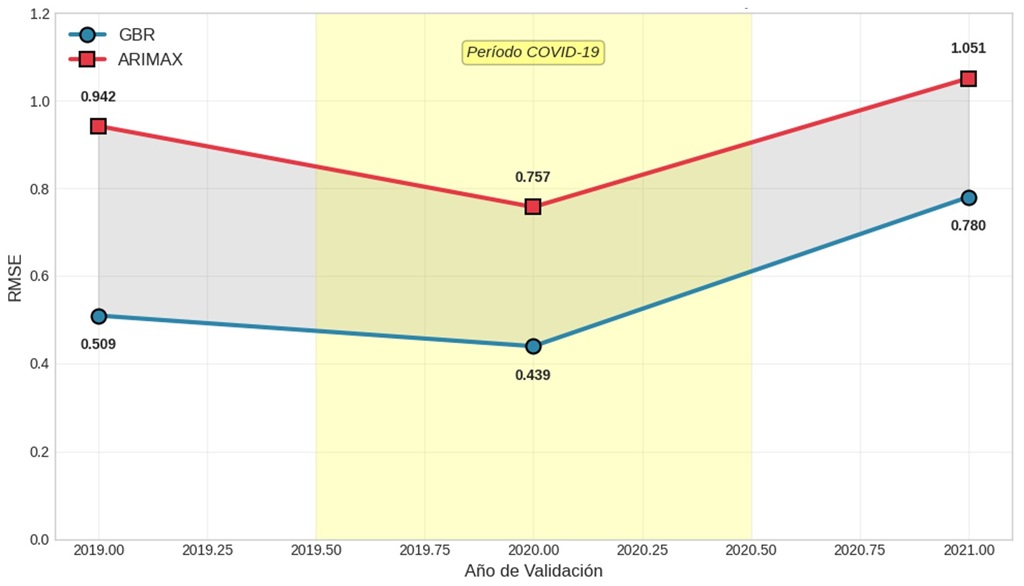
El año 2021 muestra un patrón intrigante donde ambos modelos experimentan una degradación en su desempeño ante la volatilidad post-pandemia (GBR sube a 0.780; ARIMAX a 1.051). Aunque el GBR mostró una mayor sensibilidad relativa al cambio de tendencia estructural respecto a 2020, lo crucial es que su nivel de error en el peor escenario (0.780) se mantuvo estadísticamente inferior al del ARIMAX, validando que la ventaja competitiva del algoritmo persiste incluso bajo condiciones de alta incertidumbre.
4.4. Significancia estadística
La superioridad observada del GBR podría ser resultado de variación aleatoria, especialmente considerando el tamaño relativamente modesto del conjunto de prueba (50 observaciones correspondientes a 25 departamentos en 2 años). Para abordar esta preocupación, se aplicó el test de Diebold-Mariano que evalúa formalmente si las diferencias en precisión predictiva entre dos modelos son estadísticamente significativas.
El test arrojó un estadístico DM de -4.150 con un p-valor < 0.001, proporcionando evidencia suficiente para rechazar la hipótesis nula de igual capacidad predictiva. El signo negativo del estadístico confirma que el GBR tiene sistemáticamente menor pérdida cuadrática que ARIMAX. La magnitud del estadístico (|DM| > 4) es particularmente notable, sugiriendo que las diferencias observadas son no solo estadísticamente significativas sino también sustancialmente importantes.
Este resultado es robusto incluso considerando posibles violaciones de los supuestos del test, como la potencial correlación serial en las diferencias de pérdida. La significancia extrema (p < 0.001) proporciona un margen amplio para mantener la conclusión incluso bajo correcciones conservadoras.
4.5. Importancia de variables e interpretabilidad
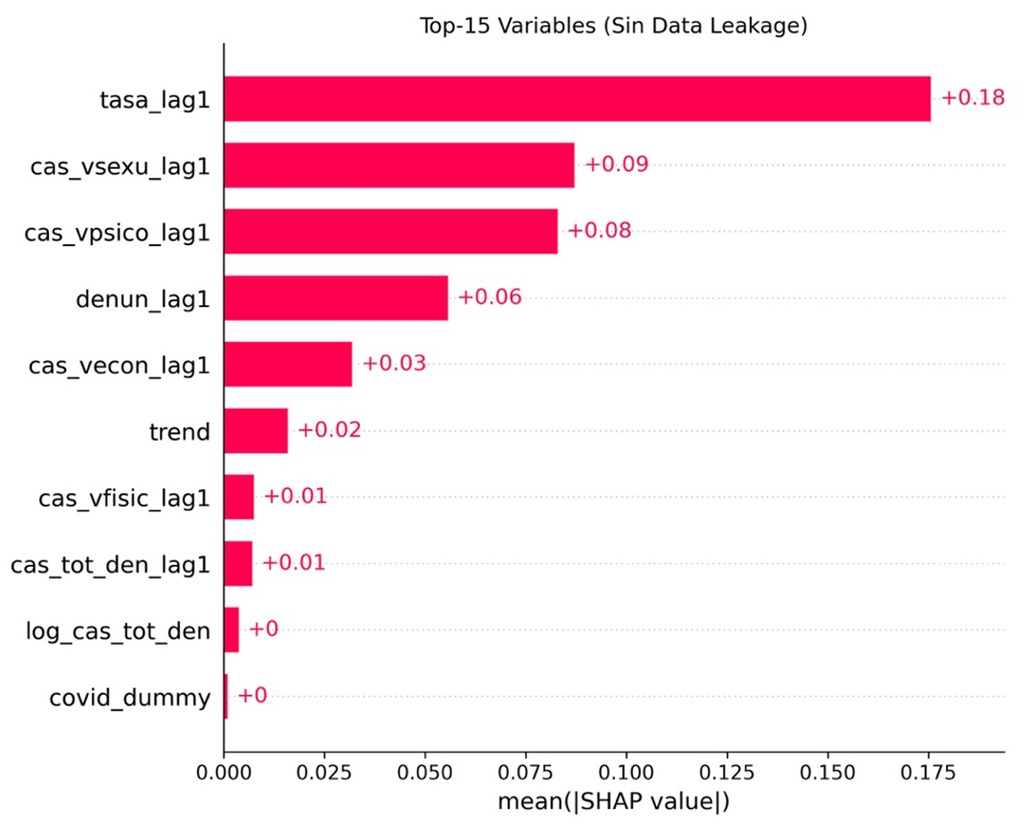
El Gráfico 2 presenta el ranking de importancia de variables según el modelo GBR optimizado. El análisis revela dos dinámicas fundamentales. En primer lugar, la variable con mayor peso predictivo es la tasa de feminicidios del año anterior (tasa_lag1), con una importancia SHAP de 0.176, lo que confirma la fuerte inercia estructural del fenómeno: la violencia feminicida tiende a persistir en las regiones donde ya es endémica.
En segundo lugar, y siendo el hallazgo más relevante para la prevención, las variables de violencia sexual (cas_vsexu_lag1: 0.087) y violencia psicológica (cas_vpsico_lag1: 0.083) emergen como los predictores de riesgo dominantes. En contraste, la violencia física (cas_vfisic_lag1) mostró una contribución marginal (0.008). Esto sugiere que las agresiones 'invisibles' o que atentan contra la dignidad y libertad sexual constituyen alertas tempranas más efectivas que las agresiones físicas previas, las cuales podrían estar subreportadas o manifestarse ya en etapas tardías del ciclo de violencia.
La Figura 5 profundiza en el rol de las variables de violencia como precursoras del feminicidio. El panel A muestra que los casos de violencia sexual rezagada (t-1) tienen la mayor importancia SHAP (0,087) entre los tipos de violencia, seguidos cercanamente por la violencia psicológica rezagada (0,083). Este hallazgo es consistente con la literatura criminológica que identifica estos tipos de violencia como precursores críticos en la escalada hacia el feminicidio.
El panel B de la Figura 5 presenta un modelo conceptual del proceso temporal, ilustrando cómo la violencia psicológica y sexual en el período t-1 puede escalar hacia formas más graves de violencia en el período t, culminando en riesgo elevado de feminicidio en t+1. La identificación de esta "ventana de intervención" entre t-1 y t tiene implicaciones profundas para el diseño de políticas preventivas, sugiriendo que las intervenciones focalizadas en mujeres que han experimentado violencia sexual o psicológica podrían prevenir desenlaces fatales.
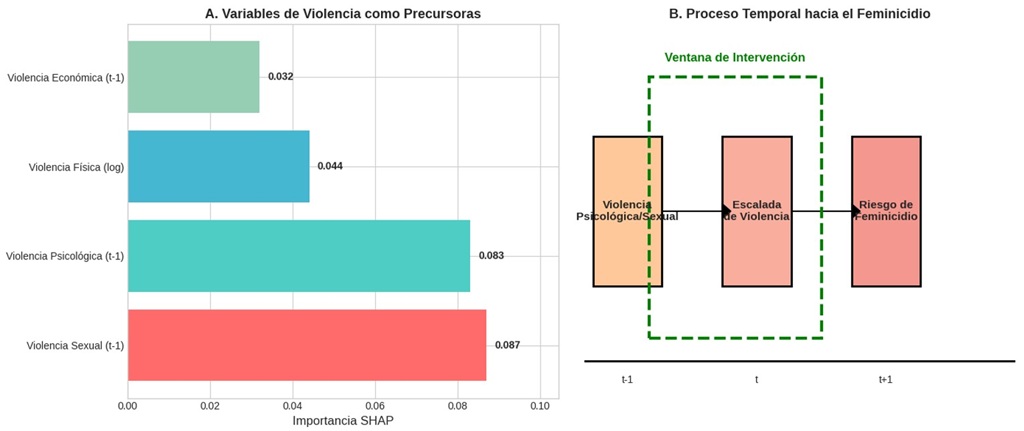
4.6. Correlaciones y patrones de violencia
El Gráfico 3 presenta una visualización integral de las correlaciones entre diferentes tipos de violencia y el feminicidio, revelando patrones complejos de interrelación. Las correlaciones más fuertes con el feminicidio se observan para la violencia sexual (r=0,82) y la violencia psicológica (r=0,75). Estos valores de correlación, sustancialmente más altos que los observados para violencia física (r=0,68) o económica (r=0,45), refuerzan los hallazgos del análisis SHAP sobre la importancia crítica de estos tipos específicos de violencia.
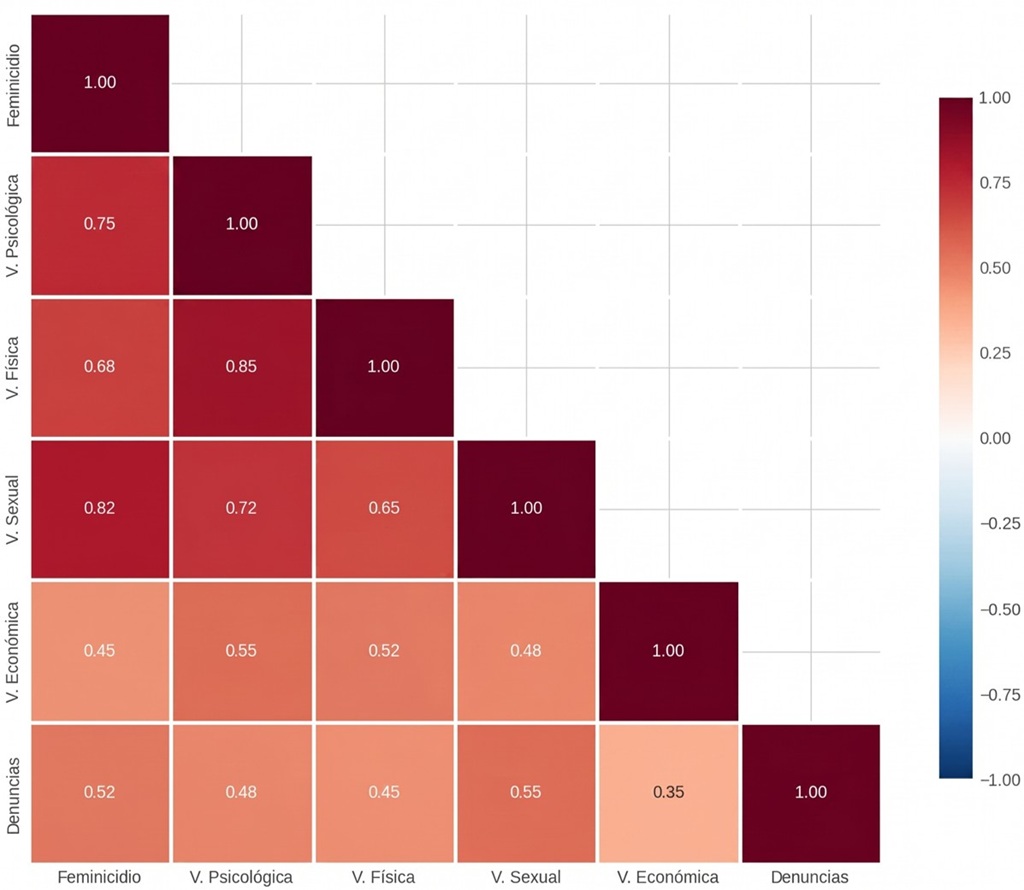
Un patrón particularmente revelador es la alta correlación entre violencia psicológica y física (r=0,85), sugiriendo que estos tipos de violencia frecuentemente coocurren. Sin embargo, la correlación más fuerte del feminicidio con violencia sexual que con la de tipo físico sugiere que la ruta hacia el feminicidio no necesariamente sigue una progresión lineal de severidad física, sino que puede involucrar dimensiones más complejas de control, dominación y deshumanización.
La correlación relativamente moderada entre denuncias y feminicidio (r=0,52) revela una paradoja preocupante: aunque las denuncias son un mecanismo crucial de protección, su correlación limitada con los desenlaces sugiere barreras significativas en la efectividad del sistema de protección. Esto podría reflejar múltiples factores, incluyendo subregistro de denuncias, respuesta institucional inadecuada o retiro de denuncias por presión o miedo.
5. Discusión
Los hallazgos de este estudio corroboran de manera contundente la primera hipótesis de investigación (H1), demostrando que el modelado algorítmico basado en Gradient Boosting Regressor (GBR) supera significativamente a las aproximaciones lineales tradicionales (ARIMAX) en la predicción del feminicidio. Esta superioridad, cuantificada en una reducción del error predictivo cercana al 45% (RMSE) y validada estadísticamente mediante el test de Diebold-Mariano (∣ DM ∣>4), no es meramente un artefacto técnico, sino que revela una característica ontológica fundamental de la violencia de género: su naturaleza compleja, dinámica y no lineal.
La literatura clásica y los modelos actuariales tradicionales han operado históricamente bajo el supuesto de linealidad y aditividad, asumiendo que el riesgo de feminicidio aumenta de manera proporcional a la acumulación de factores de riesgo estáticos. Sin embargo, el desempeño inferior del modelo ARIMAX en este estudio sugiere que dicha aproximación es insuficiente para capturar la "arquitectura del desastre" que precede al crimen. El feminicidio no es el resultado de una suma aritmética de agresiones, sino el colapso de un sistema de contención, un fenómeno que se asemeja más a un cambio de fase en sistemas complejos que a una progresión lineal simple. El algoritmo GBR, al operar mediante la construcción secuencial de árboles de decisión que corrigen los errores residuales de sus predecesores, logra "aprender" estas interacciones de alto orden que escapan al ojo humano y a la estadística paramétrica.
Específicamente, la capacidad del modelo para mantener su robustez durante el choque estructural de la pandemia por COVID-19 (2020) (un periodo donde las dinámicas de convivencia y denuncia se transformaron radicalmente) evidencia que los algoritmos de aprendizaje automático pueden capturar patrones latentes de adaptación criminal. Mientras que los modelos lineales tendieron a sobreestimar o subestimar el riesgo basándose en la inercia histórica, el GBR identificó cómo las restricciones de movilidad (variable dummy COVID) interactuaron de forma no lineal con la violencia intrafamiliar, exacerbando el riesgo en contextos de aislamiento.
Este hallazgo tiene implicaciones profundas para la criminología computacional: sugiere que la precisión en la predicción del feminicidio depende menos de la cantidad de datos históricos y más de la capacidad del modelo para detectar "puntos de inflexión" o umbrales críticos donde la violencia pasa de ser un patrón crónico a convertirse en una amenaza letal inminente.
Uno de los aportes más reveladores y contraintuitivos de esta investigación reside en la jerarquización de los factores de riesgo identificada mediante el análisis de valores SHAP, lo cual permite responder y matizar la segunda hipótesis (H2). Contrario al sentido común jurídico y a ciertas prácticas policiales que suelen priorizar la violencia física visible (lesiones, golpes) como el indicador primario de urgencia, nuestro modelo identificó a la violencia sexual rezagada y a la violencia psicológica como los precursores de mayor letalidad, superando en importancia predictiva a la violencia física.
Este hallazgo empírico encuentra un respaldo teórico robusto en la teoría del control coercitivo postulada por Evan Stark (2007)Ref22. Desde esta perspectiva, el feminicidio no debe entenderse solo como el desenlace de un "ataque de furia" o una agresión física desmedida, sino como la culminación de un proceso estratégico de dominación donde el agresor busca anular la autonomía de la víctima. En este marco, la violencia sexual no es solo un atentado contra la integridad física, sino un acto de "desposesión" y control total sobre el cuerpo y la subjetividad de la mujer.
El hecho de que el algoritmo asigne un peso predictivo superior (∼9%) a la violencia sexual sugiere que esta modalidad de agresión actúa como un "marcador de propiedad" por parte del agresor, indicando un nivel de radicalización en su afán de dominio que a menudo precede al aniquilamiento físico de la víctima.
Del mismo modo, la alta relevancia de la violencia psicológica confirma que el "cerco" al que se somete a la mujer (mediante aislamiento, intimidación, degradación y control económico) es el caldo de cultivo donde se gesta la letalidad. La violencia física, aunque grave, puede ser episódica; en cambio, la violencia psicológica y sexual denota un estado de sitio permanente. Al validar empíricamente que estos factores "invisibles" o menos penalizados son, en realidad, las señales de alarma más estridentes, este estudio desafía los protocolos actuales de valoración de riesgo (como las fichas de valoración policial en Perú) que a menudo subestiman las denuncias donde "no hay sangre" o lesiones visibles. El modelo nos está diciendo, a través de los datos, que el riesgo letal se esconde a menudo en el silencio de la coacción psicológica y en la intimidad de la violencia sexual, validando así las tesis feministas sobre el carácter estructural y político de la violencia doméstica (Walker, 1979Ref25; Hooks, 2000Ref9).
El análisis temporal de los predictores, facilitado por la estructura de rezagos (t-1) del modelo, permite abordar la tercera hipótesis (H3) desde una perspectiva de gestión pública. La detección de una correlación significativa entre las denuncias del año anterior y la tasa de feminicidio actual confirma la existencia de una "ventana de oportunidad" para la intervención estatal. Este lapso temporal entre la alerta administrativa (la denuncia) y el desenlace fatal (el feminicidio) representa el fracaso o el éxito potencial del sistema de protección.
Sin embargo, los resultados también exponen una paradoja preocupante: la correlación entre el volumen de denuncias y la reducción de feminicidios es más débil de lo esperado (r=0,52). Esto podría interpretarse de dos formas. Una lectura optimista sugeriría que el sistema está funcionando parcialmente y que muchas denuncias derivan en protección efectiva, evitando la muerte. No obstante, una lectura crítica, alineada con los reportes de la Defensoría del Pueblo y estudios previos (García y Benavides, 2024)Ref6, apunta a la ineficacia de la respuesta institucional. El hecho de que la inercia histórica (tasa de feminicidios previas) sea el predictor más potente (∼62%) sugiere una "dependencia de la trayectoria" (path dependence): los departamentos que son violentos hoy tienden a serlo mañana, independientemente del volumen de denuncias procesadas. Esto evidencia una fractura en la cadena de protección: la denuncia está sirviendo como un registro administrativo del abuso, pero no necesariamente como un activador de mecanismos de seguridad efectivos. El modelo detecta que donde hubo denuncias por violencia sexual y psicológica el año pasado, es altamente probable que ocurra un feminicidio este año. Esto implica que el Estado está recibiendo la "señal" de alerta, pero no está logrando interrumpir el circuito de violencia durante esa ventana de tiempo crítica. La "intervención oportuna" que postula la H3, por tanto, no requiere solo predecir el evento, sino transformar la arquitectura institucional para que la respuesta ante una denuncia por violencia psicológica sea tan contundente e inmediata como ante una agresión física grave.
Finalmente, la discusión sobre la aplicabilidad de estos modelos en un país heterogéneo como el Perú no puede obviar las dimensiones éticas y territoriales. El análisis de factores contextuales reveló que la densidad poblacional y la ruralidad actúan como moduladores del riesgo. En departamentos con alta dispersión geográfica y baja presencia estatal, como Madre de Dios o zonas de la selva, el modelo podría estar subestimando el riesgo real debido al subregistro de denuncias ("cifra negra").
La implementación de sistemas de Inteligencia Artificial en la política criminal conlleva el riesgo de reproducir sesgos históricos. Si el algoritmo "aprende" que se denuncia menos en zonas rurales indígenas, podría asignar erróneamente un perfil de "bajo riesgo" a territorios que, en realidad, sufren de desprotección estructural y barreras lingüísticas o culturales para el acceso a la justicia. Por ello, es imperativo que cualquier despliegue de estas herramientas se realice bajo un enfoque de "human-in-the-loop" (humano en el bucle), donde el juicio experto de los operadores de justicia contextualice la predicción algorítmica. Además, la identificación de "perfiles de riesgo" basados en variables socioeconómicas (como dependencia económica o nivel educativo, asociados a la violencia económica) debe manejarse con extrema cautela para no estigmatizar a poblaciones vulnerables. El objetivo del modelo predictivo no es vigilar a las potenciales víctimas o a comunidades específicas, sino vigilar la inacción estatal y priorizar recursos escasos hacia los casos que presentan patrones de alta letalidad invisible (sexual/psicológica). La ética de la IA en este contexto (UNESCO, 2021)Ref23 exige que la predicción sirva exclusivamente para activar protocolos de protección garantistas y nunca para restringir derechos o revictimizar a quienes buscan ayuda.
6. Conclusiones
El modelo de Machine Learning desarrollado (Gradient Boosting Regressor) ha demostrado una alta precisión predictiva en comparación con los modelos tradicionales (actuariales y SPJ), destacando especialmente su capacidad para capturar la no linealidad y las dinámicas complejas que preceden al feminicidio.Esta superioridad técnica sugiere que las herramientas algorítmicas pueden complementar eficazmente el juicio humano en la valoración del riesgo.
Las variables más influyentes identificadas confirman la teoría de la escalada de violencia: la inercia histórica del fenómeno (número de víctimas previas) y las denuncias anteriores por violencia psicológica y sexual constituyen los precursores más críticos. Asimismo, factores contextuales como la densidad poblacional (asociada a la ruralidad o urbanidad) juegan un rol modulador en el riesgo, validando la necesidad de enfoques territoriales diferenciados. El uso de valores SHAP permitió desglosar la "caja negra" del algoritmo, asignando una importancia relativa transparente a cada factor de riesgo, lo que permite pasar de una prevención genérica a estrategias focalizadas.
A la luz de estos hallazgos, se plantean implicaciones directas para la política pública. En primer lugar, se recomienda la implementación de sistemas de alerta temprana que integren estos modelos predictivos en la gestión de casos del MIMP y la PNP. Simultáneamente, resulta imperativo el fortalecimiento del registro de datos para mejorar su interoperabilidad y reducir el subregistro, especialmente en zonas rurales. Asimismo, es fundamental la capacitación institucional del personal de primera línea en la interpretación de estas alertas probabilísticas, enfatizando su rol de apoyo a la decisión humana. Finalmente, cualquier aplicación tecnológica debe garantizar la ética y privacidad mediante protocolos estrictos que eviten la revictimización y la estigmatización territorial.
Referencias bibliográficas
1) Bernal-Monroy, E. R., Castañeda-Monroy, E. D., Rentería-Ramos, R. R., Campaña-Bastidas, S. E., Barrera, J., Palacios-Yampuezan, T. M., González-Gustin, O. L., Tobar-Torres, C. F., y Ceballos-Villada, Z. R. (2025). Detection of victimization patterns and risk of gender violence through machine learning algorithms. Informatics, 12(1), 21. https://doi.org/10.3390/informatics12010021
2) Comisión Económica para América Latina y el Caribe (CEPAL). (2024). Violencia feminicida en cifras – América Latina y el Caribe: Actuar con sentido de urgencia para prevenir y poner fin a los feminicidios. Observatorio de Igualdad de Género de América Latina y el Caribe. Disponible en: https://is.gd/IbwDlC
3) Congreso de la República del Perú. (2015, 23 de noviembre). Ley N.° 30364: Ley para prevenir, sancionar y erradicar la violencia contra las mujeres y los integrantes del grupo familiar. Diario Oficial El Peruano. Disponible en: https://www.mimp.gob.pe/files/transparencia/ley-30364.pdf
4) Cruz-Mendoza, M. C., Meléndez-Armenta, R. A., Canul-Reich, J., y Muñoz-Benítez, J. (2025). Machine learning applied to improve prevention of, response to, and understanding of violence against women. Informatics, 12(2), 40. https://doi.org/10.3390/informatics12020040
5) Defensoría del Pueblo. (2023). Informe sobre denuncias por violencia contra la mujer: Avances y pendientes. Disponible en: https://is.gd/6YhHaU
6) García, A., y Benavides, L. (2024). Identificación de factores criminológicos que explican el riesgo de feminicidio: 2009-2023. Ministerio de Justicia y Derechos Humanos. Disponible en: https://is.gd/pl3nrq
7) González-Prieto, Á., Brú, A., Nuño, J. C., y González-Álvarez, J. L. (2023). Hybrid machine learning methods for risk assessment in gender- based crime. Knowledge- Based Systems, 260, 110130. https://doi.org/10.1016/j.knosys.2022.110130
8) Heise, L. L. (1998). Violence against women: An integrated, ecological framework. Violence Against Women, 4(3), 262–290. https://doi.org/10.1177/1077801298004003002
9) Hooks, B. (2000). Feminism is for everybody: Passionate politics. South End Press.
10) Instituto Nacional de Estadística e Informática (INEI). (2024a). Perú: Comportamiento de los indicadores del mercado laboral a nivel nacional y en 26 ciudades. Disponible en: https://is.gd/oP9hpG
12) Lima, V., y Almeida de Oliveira, J. (2024). Identifying risk patterns in Brazilian police reports preceding femicides: A long short-term memory (LSTM) based analysis. arXiv. https://doi.org/10.48550/arXiv.2401.12980
13) Loinaz, I. (2025). Misconceptions about intimate partner violence risk assessment algorithm in the Basque Country: A reply to Valdivia, Hyde- Vaamonde, & García- Marcos (2024). AI & Society. https://doi.org/10.1007/s00146-025-02192-2
14) Lundberg, S. M., & Lee, S.-I. (2017). A unified approach to interpreting model predictions. Advances in Neural Information Processing Systems, 30. https://dl.acm.org/doi/10.5555/3295222.3295230
15) Ministerio de la Mujer y Poblaciones Vulnerables. (2025). Boletín nacional 2025: Indicadores de violencia contra las mujeres y los integrantes del grupo familiar. Disponible en: https://is.gd/HsEriI
16) Naciones Unidas. (1993). Declaración sobre la eliminación de la violencia contra la mujer. Disponible en: https://is.gd/vlyjFl
17) ONU Mujeres. (2023). Cinco datos clave sobre el femicidio. Disponible en: https://is.gd/IsX3O6
18) Organización Panamericana de la Salud, y Centros para el Control y la Prevención de Enfermedades. (2014). Violencia contra las mujeres en América Latina y el Caribe. Disponible en: https://is.gd/MRdCQf
19) Presidencia de la República del Perú. (2018, 29 de julio). Decreto Legislativo N.º 1368: Decreto Legislativo que crea el Sistema Nacional Especializado de Justicia para la protección y sanción de la violencia contra las mujeres e integrantes del grupo familiar. Diario Oficial El Peruano. Disponible en: https://is.gd/oL0Bme
20) Rodríguez-Rodríguez, I., Rodríguez, J.-V., Pardo-Quiles, D.-J., Heras-González, P., y Chatzigiannakis, I. (2020). Modeling and forecasting gender-based violence through machine learning techniques. Applied Sciences, 10(22), 8244. https://doi.org/10.3390/app10228244
21) Saboya, N., Sullón, A. A., & Loaiza, O. L. (2019). Predictive model based on machine learning for the detection of physically mistreated women in the Peruvian scope. Proceedings of the 3rd International Conference on Advances in Artificial Intelligence, 18–23. https://doi.org/10.1145/3369114.3369143
22) Stark, E. (2007). Coercive control: The entrapment of women in personal life. Oxford University Press.
23) UNESCO. (2021). Recomendación sobre la ética de la inteligencia artificial. Disponible en: https://unesdoc.unesco.org/ark:/48223/pf0000381137
24) Viñas-Racionero, R., Raghavan, C., Soria-Verde, M. Á., Scalora, M. J., Santos-Hermoso, J., González-Álvarez, J. L., y Garrido-Antón, M. J. (2025). Enhancing the assessment of coercive control in Spanish femicide cases: A nationally representative qualitative analysis. Journal of Family Violence, 40(2), 237– 248. https://doi.org/10.1007/s10896-023-00628-1
25) Walker, L. E. (1979). The battered woman. Harper & Row.
Breve curriculum de los autores
Ruiz, Rubén Ángel
Rubén Ángel Ruiz es Magíster en Administraciòn estratégica de Negocios por la Pontificie Universidad Católica del Perú. Actualmente se desempeña como docente universitario e investigador en la Universidad Tecnológica del Perú. Sus líneas de investigación se centran en la aplicación de algoritmos de Machine Learning y ciencia de datos para el modelado de fenómenos sociales complejos, criminología computacional y el desarrollo de sistemas de alerta temprana para la gestión pública.
Venegas, Pedro B.
Pedro B. Venegas es Magíster en Administraciòn estratégica de Negocios por la Pontificie Universidad Católica del Perú. Actualmente se desempeña como Director de Investigación de la Facultad de Ciencias de la Empresa y docente investigador en la Universidad Continental. Especialista en competitividad empresarial y comercio internacional. Sus intereses de investigación abarcan los métodos cuantitativos para la economía y la empresa, el análisis de competitividad en sectores productivos (agrícola y minero) y la globalización económica.
Calle, Margarita E.
Margarita E. Calle es Magíster en Educación con mención en Docencia en Educación Superior por la Universidad Continental. Actualmente se desempeña como docente universitario e investigadora adscrita a la Facultad de Ciencias de la Empresa de la Universidad Continental. Especialista en economía aplicada y metodología de la investigación científica. Sus intereses de investigación abarcan el desarrollo económico regional, la gestión educativa y el análisis de políticas públicas con enfoque social.